
La loi de Zipf à l’origine d’une observation SEO bien connue…
Puisque dans les articles précédents on était pas mal branché mathématique, pourquoi ne pas continuer ? En faisant des recherches sur les principes de TF-IDF et sur le cosinus de Salton, j’ai découvert une loi statistique qui se glissait par-ci par-là, lorsque les thèmes fréquence de mots clés, pertinence lexicale, occurrence d’un terme… apparaissaient. Il s’agit de la loi de Zipf.
Est-ce que la loi de Zipf représente un intérêt particulier pour le SEO ? Je pense que oui. Elle décrit un phénomène statistique qui se retrouve aujourd’hui dans beaucoup d’entités de notre quotidien. Et pour ma part je suis persuadé qu’elle influence largement ce bon vieux Googlebot 😉 C’est parti donc pour la loi de Zipf !
Mais qui donc est ce Zipf, et qu’a-t-il découvert ?
George Kingsley Zipf est un linguiste et un philologue (qui étudie la linguistique historique à partir de documents écrits) américain né au début du 20eme siècle. Il est en quelques sortes un des pères fondateurs des statistiques appliquées à la linguistique. Pour illustrer ses travaux, il décide de procéder à une analyse de l’œuvre « Ulysse » de James Joyce, sur laquelle il décide de dénombrer le nombre total de mots, qu’il classe ensuite par occurrence. Voici un extrait de son observation :
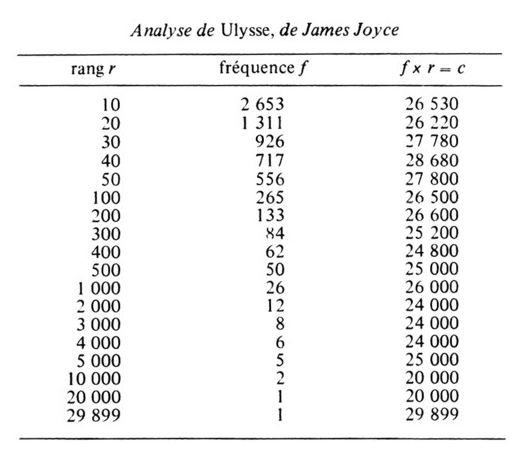
Son résultat montre qu’il existe une relation entre la fréquence d’utilisation d’un mot et son rang dans un texte volumineux. La loi dit littéralement que « la fréquence d’utilisation d’un mot dans un texte volumineux était inversement proportionnelle à son rang ». Autrement dit, le mot le plus fréquent apparaît 2653 fois et le mot le moins fréquent apparait 1 fois, d’après les résultats obtenus sur le tableau ci-dessus.
Si G.K Zipf observe cela pour « Ulysse », il découvrira que cette loi s’observe également dans de nombreuses langues et dans de nombreux types d’ouvrages.
La loi de Zipf est donc une observation empirique, c’est-à-dire une observation fondée sur l’évidence et l’expérimentation. Méthode appréciée par les scientifiques, elle a pour but de tester une hypothèse à partir d’un objectif défini au préalable.
Etude mathématique de cette loi empirique
Pour mieux comprendre l’intérêt de cette loi pour le SEO, nous allons procéder à une petite analyse mathématique de cette loi de Zipf. Nous allons commencer par se référer à des résultats simplifiés, comparé à ceux que Zipf a obtenus à la suite de son analyse de l’œuvre de James Joyce.
Les résultats simplifiés ont pour but de faciliter la compréhension de la démonstration. Si à première vue ils semblent totalement différents des résultats détaillés plus haut, ils respectent néanmoins un ordre de proportion similaire à ceux découvert par Zipf.
Partons donc de cette base que Wikipédia nous fournit. Je vais aller un peu plus loin, en attribuant des mots au hasard à chaque condition. Imaginons donc que dans un corpus de texte, nous retrouvions ceci :
- « SEO » est le mot le plus courant (rang 1) car il apparait 8000 fois
- « SEA » est le dixième mot le plus courant (rang 10) car il apparait 800 fois
- « SEM » le centième (rang 100), car il apparait 80 fois
- « BOT » le millième (rang 1000) car il apparait 8 fois.
A première vue, ces résultats semblent trop beaux pour être vrai, c’est pourquoi je vous ai bien stipulé avant que ces résultats étaient simplifiés.
La loi de Zipf annonce que
« Si x est le xem mot le plus fréquent dans un texte, il doit alors avoir la fréquence f(x)=K/x, où K est une constante (indépendante de n) »
Traduction : si SEO est le 1er mot le plus fréquent dans un texte, il doit alors avoir la fréquence f(1)=K/1.
Traduction (bis) : si SEM est le 100eme mot le plus fréquent dans un texte, il doit alors avoir la fréquence f(100)=K/100
Rappel de la définition d’une fonction : c’est un procédé mathématique qui associe à un nombre, un unique autre nombre (appelé l’image). Souvent appelé f, on écrit de cette manière une fonction : f(x). Une fonction peut également être représentée graphiquement dans un plan (voir l’article sur le Cosinus de Salton, pour la définition d’un plan ou d’un espace vectoriel).
Si l’on décide de déterminer que K=1, nous sommes confrontés à une fonction de type f(x)=1/x et voici les résultats de corpus de texte précédent :
SEO : f(1)=1/1 donc f(1)=1
SEA : f(10)=1/10 donc f(10)=0.1
SEM : f(100)=1/100 donc f(100)=0.01
BOT : f(1000)=1/1000 donc f(1000)=0.001
Et maintenant si je représente cette fonction f(x)=1/x sur un plan, j’arrive à une courbe ressemblant étrangement à ceci (et là, amis SEO, un déclic vous parviendra forcement !!! 🙂 )
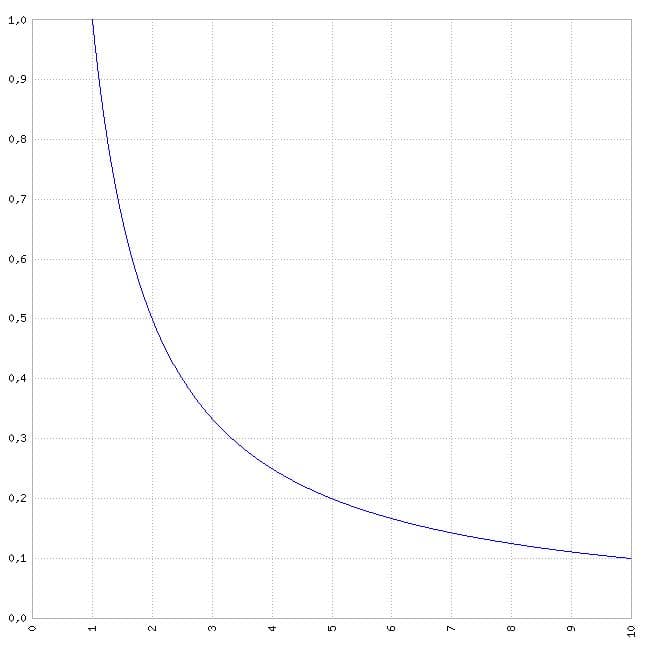
N’est-elle pas magnifique cette courbe de « Longue Traine » ? 🙂
Pour raccorder un peu les résultats graphiques et les résultats calculés, nous pouvons placer nos différents points obtenus un peu plus haut. Pour rappel, pour une fonction de type f(x)=x, le chiffre entre parenthèses se place en abscisse, et le nombre après le « = » en ordonnées. En mathématique, on dit par exemple que 0.1 est l’image de 100, 0.01 est l’image de 100 etc… Donc :
- SEO à pour coordonnées (1;1)
- SEA (10;0.1)
- SEM (100;0.01)
- BOT (1000;0.01)
Malheureusement les résultats simplifiés m’empêchent de placer tous les points sur la courbe. C’est pourquoi c’est un exercice que je vais peut-être vous laisser faire par vous même. Avec la courbe ci-dessus, nous pouvons placer aisément les point SEO et SEA. En ce qui concerne les autres, il faudrait un graphique sur une échelle un peu plus grande, et surtout plus précise… Ce qui n’est pas l’objectif premier de cet article 😉
La loi de Zipf, une illustration plutôt concrète de la Longue Traine
Cette courbe, en référencement naturel, nous la connaissons bien. Il s’agit donc de la représentation graphique de la Longue Traine, ou Long Tail en Anglais. Pour ceux qui ne seraient pas familiers avec le terme, la Longue Traine (en ce qui concerne le SEO) traduit le fait qu’une bonne part du trafic sur un site peut provenir d’un très grand nombre de mots clés ne présentant pas de potentiel réellement grand. 100 mots clés à faible potentiel, peuvent par accumulation vous rapporter plus de trafic qu’un seul mot clé à fort potentiel.
La démonstration statistique de Zipf est apparue bien avant la notion de « Longue Traine ». En fait, elle illustrait le fait que chaque langage peut être étudié par la même approche. C’est indirectement de cette manière que des cryptographes peuvent décoder des messages, ou encore comprendre de nouvelles formes de langages. En partant des expressions fréquentes (haut de la courbe), on parvient petit à petit à comprendre d’autres expressions moins fréquentes (vers le bas de la courbe).
Google est-il le plus grand cryptographe de tous les temps ?
De mon point de vue, il est évident que Google se sert de cette méthode pour comprendre le sens de nos contenus. De cette manière, il est capable de déterminer une thématique et de la décliner pour la préciser. L’éternelle question « Comment Google distingue-t-il une Jaguar avec un jaguar » trouve sa réponse (à mon sens) dans cette approche. En descendant au fur et à mesure la courbe de la loi de Zipf, Google est capable petit à petit de saisir le sens du contenu. C’est pourquoi, je pense que pour un SEO il est crucial de travailler cette approche lexicale. Si Google utilise réellement cette base mathématique, alors il est évident qu’un travail minutieux de Longue Traine facilitera largement la compréhension de votre site par Google.
Je pense donc, que Google est le plus grand cryptographe du monde ! 😉 Bon, il ne remplacera jamais le libre arbitre et l’interprétation d’un humain, certes, mais imaginez le nombre de langues, de langages, de codes qu’il est capable d’interpréter, grâce à cette loi de Zipf ?
Le Cosinus de Salton, TF-IDF, et la loi de Zipf, sont je pense de bonnes petites bases pour comprendre le travail de Google d’un point de vue lexical sur nos sites. On peut je pense mieux cerner ses envies, et ses attentes. Maintenant, y a-t-il un réel intérêt SEO. Je pense que chacun a le droit de se faire sa propre opinion. Pour ma part, je pense que cela permet d’avoir un regard un peu plus affûté sur la compréhension des contenus par Google, et donc par conséquent, cela impact directement notre travail.
Pas facile de résumer la loi de Zipf, mais j’espère que cela vous a plu. En tout cas n’hésitez pas à partager l’article si vous en mourrez d’envie, et surtout utilisez les commentaires si une notion vous échappe, ou si tout simplement vous ne partagez pas mon point de vue 🙂
Un grand merci à Benjamin Yeurc’h (alias Benjaminyeurix), Référenceur à Rennes pour la relecture de l’article 🙂
Oui, merci pour ta réponse bien détaillée ! J’avais complètement zappé l’aspect « local » qui est une vraie mine d’or à ce propos.
Très intéressant ! Donc, si je suis le raisonnement de l’exemple pris en fin d’article, Google arriverait à savoir qu’une page parle de voiture en mentionnant la marque Jaguar dès lors qu’il trouverait des meta-mots liés à la conduite en véhicule 4 roues de luxe ou empruntés au domaine de la mécanique automobile ? Mais n’est-ce pas déjà ce qui se passe naturellement dans un article ?
Hello !
Oui bien évidemment. Il le fait pour un article de manière parfaitement « naturel ».
L’exemple simplifié de l’article explique la notion de compréhension de thématiques d’un site en général, à travers notamment l’analyse des mots clés.
J’ai peut-être un exemple plus concret.
Prenons un blog de la thématique générale : -> La stratégie digitale
Thématique plus détaillée : -> Visibilité et stratégie digitale
Thématique encore plus détaillé : -> SEO, solution de visibilité dans une stratégie digitale.
…
C’est cette spécification de thématique qui construit la courbe de Zpif, et qui permet à Google de comprendre vraiment précisément la/les thématique(s) générale(s), avec ses spécifications.
L’exemple de contenus géo localisés peut aussi très bien illustrer cette approche empirique.
Voila, je sais pas si ça répond bien à la question ? 😀